V predchádzajúcich článkoch seriálu o vysvetliteľnej umelej inteligencii (AI) sme predstavili tri dôležité otázky z tejto oblasti: Aké vlastnosti by malo mať dobré vysvetlenie? Ako merať kvalitu vysvetlení predpovedí modelov umelej inteligencie? Ako automaticky nájsť taký algoritmus vysvetliteľnej AI, ktorý bude poskytovať dobré vysvetlenia pre konkrétny model, dáta a úlohu?

V tomto príspevku nadviažeme na tieto otázky a ukážeme si jeden zo spôsobov, ako nielen získať dobré vysvetlenia, ale zároveň overiť, do akej miery rôzne vysvetlenia pomáhajú ľuďom pri plnení úloh.
Vlastnosti dobrých vysvetlení
Podobne ako v strojovom učení a umelej inteligencii, aj vo vysvetliteľnej AI existuje množstvo algoritmov, po ktorých môže používateľ siahnuť. Ak si má informovane vybrať ten správny, potrebujeme mechanizmus, vďaka ktorému dokážeme rôzne algoritmy porovnávať. Inými slovami, potrebujeme vedieť zmerať, ktoré vysvetlenia sú lepšie a ktoré horšie v kontexte danej úlohy a z pohľadu kritérií stanovených používateľom.
Ešte predtým, než začneme s vlastným meraním, sústreďme sa na to, čo budeme merať, čiže aké vlastnosti by malo mať dobré vysvetlenie. Na prvej úrovni hovoríme, že by malo vyvažovať dva komponenty – zrozumiteľnosť a vernosť. Zrozumiteľnosť kvantifikuje, do akej miery sú používatelia schopní vysvetleniu porozumieť. Napríklad či neobsahuje priveľa nepodstatných informácií a či používateľov nezahltí. Vernosť hovorí, do akej miery vysvetlenie opisuje skutočné správanie a rozhodovací proces modelu. Napríklad ak nám vysvetlenie tvrdí, že sentiment vety Dnes je pekné počasie model určil ako pozitívny najmä pre slovo pekné, vernosť meria, či to tak naozaj bolo a či sa náhodou model nerozhodol podľa iného slova vo vete. Každý z komponentov môžeme ďalej rozdeliť na vlastnosti, ktoré opisujú ich rôzne aspekty (pozri Quark 3/2023).
Meranie kvality
Akým spôsobom vieme tieto vlastnosti zmerať? Rozlišujeme dve skupiny prístupov k vyhodnocovaniu kvality vysvetlení – vyhodnocovanie zamerané na človeka a vyhodnocovanie zamerané na funkcionalitu. Pri prvej vychádzame z predpokladu, že adresátom vysvetlení je človek, a preto je potrebné do procesu vyhodnocovania zapojiť ľudí. Pri druhej skupine je zasa cieľom kvantitatívne a automatizované vyhodnotenie kvality vysvetlení, najčastejšie prostredníctvom tzv. proxy (zástupných) metrík.
Oba typy vyhodnocovania majú svoju nezastupiteľnú úlohu a dopĺňajú sa. Vyhodnocovanie zamerané na funkcionalitu je možné výhodne použiť na optimalizáciu algoritmu vysvetliteľnej AI tak, aby vytváral čo najlepšie vysvetlenia. Ak ho však neskombinujeme s vyhodnocovaním zameraným na človeka, nevieme presvedčivo odpovedať na tú najdôležitejšiu otázku, a to do akej miery vysvetlenia pomáhajú človeku pri plnení úloh (pozri Quark 4/2023).
Ako overiť, či zdanlivo najlepšie vysvetlenia človeku pomôžu najviac? Predstavte si, že ste sa presýtili toho, ako ľahko sa na sociálnych sieťach šíria škodlivé dezinformácie. Preto ste sa rozhodli vytvoriť vlastnú sociálnu sieť, na ktorej sa proti nim bude aktívne bojovať. Po krátkom čase počet používateľov siete prekročil prvý milión. Zároveň však narástla aj jej atraktivita pre zámerných šíriteľov dezinformácií. Napriek tomu, že ste s tým počítali a dopredu ste vyškolili niekoľko administrátorov, je počet dezinformácií taký veľký, že stíhate skontrolovať iba zlomok z nich.
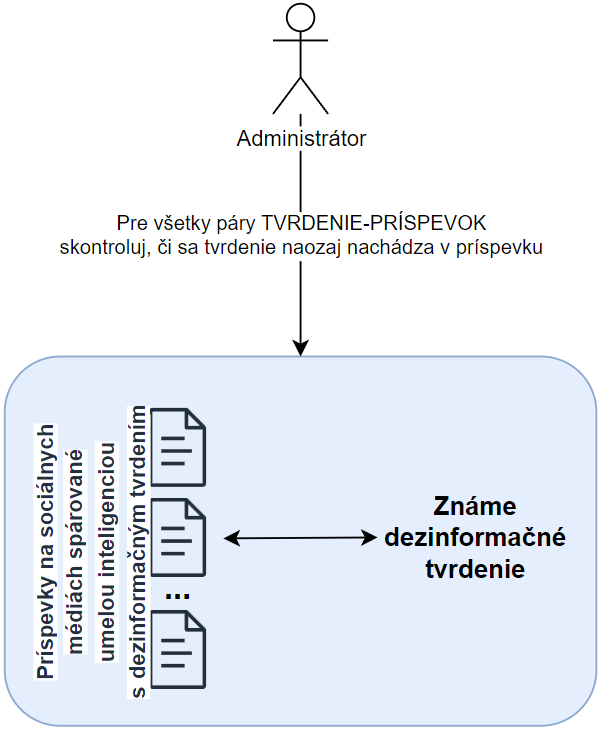
Použitie umelej inteligencie…
Rozhodnete sa svojim administrátorom pomôcť a vytvoríte pre nich nástroj založený na strojovom učení. Ten má k dispozícii databázu najaktuálnejších dezinformácií, ktoré sa šíria vo verejnom priestore, a priebežne príspevky kontroluje. Namiesto toho, aby administrátori čítali každý príspevok, dostanú preriedený zoznam tých, ktoré nástroj identifikoval ako potenciálne dezinformačné, a teda pravdepodobne obsahujú niektoré zo známych dezinformačných tvrdení. Úlohou administrátora je skontrolovať každý takýto príspevok a rozhodnúť, či má byť skrytý, alebo nie. Kontrola človekom je dôležitá, pretože je nevyhnutné sa uistiť, že príspevok je naozaj škodlivý a porušuje pravidlá sociálnej siete, keďže platí sloboda slova.
Tento nástroj ušetrí administrátorom množstvo času. Problémom však je, že niektoré príspevky môžu byť dlhé a dezinformačné tvrdenie sa skrýva až na ich konci. Navyše dezinformácia môže tvoriť len drobnú časť celého príspevku (často zámerne) a znieť na prvý pohľad odlišne od pôvodného dezinformačného tvrdenia (použitie parafráz). Preto musia administrátori často prečítať celý príspevok, kým zistia, či sa v ňom dané tvrdenie nachádza, alebo nie. Je čas vylepšiť váš nástroj.

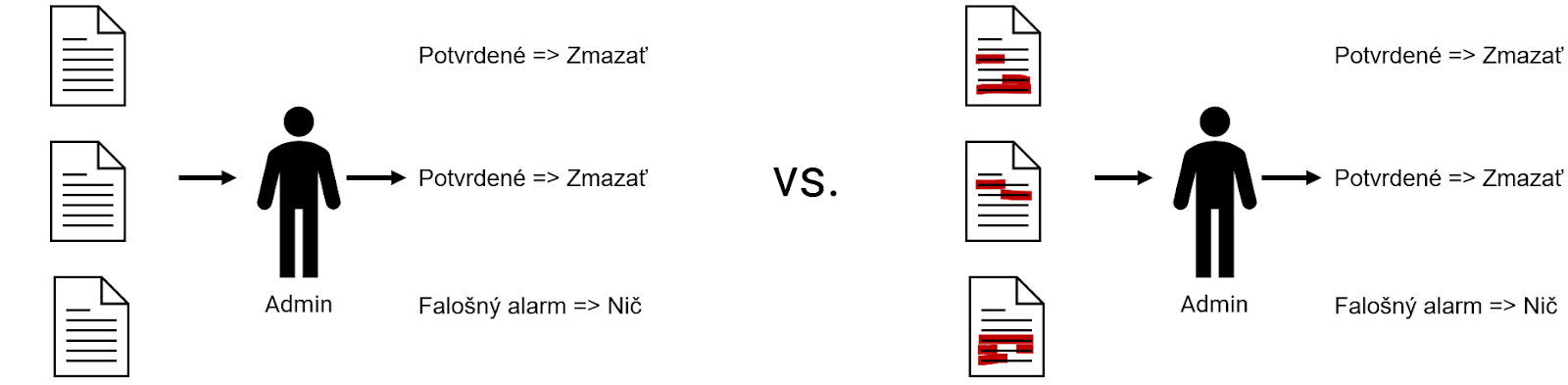
… a vysvetliteľnej AI
V ďalšom prípade chcete administrátorom nielen ukázať príspevky, ale zároveň v nich aj vyznačiť konkrétne (krátke) časti, ktoré model AI vyhodnotil ako dezinformáciu. Preto sa rozhodnete siahnuť po vysvetliteľnej AI, aby vám model povedal nielen čo (tento príspevok obsahuje dezinformáciu X), ale aj prečo alebo kde (dezinformácia X je na konci druhého odseku). Hypotézou je, že vďaka tomu budú musieť administrátori čítať výrazne menej textu a stihnú skontrolovať viac príspevkov, čo povedie k skultivovaniu diskusie.
Keď však otvoríte dokumentáciu jednej z populárnych knižníc, ktorá implementuje mnohé algoritmy vysvetliteľnej AI (napr. Captum), zistíte, že takýchto algoritmov je veľké množstvo. Ktorý teda bude ten najlepší? Môžete sa napríklad spoľahnúť na svoje šťastie a náhodne si vybrať niektorý z algoritmov (No ako nastaviť jeho parametre?) alebo náhodne vyskúšať niekoľko z nich (Ktoré a s akými parametrami?). Spôsobom, vďaka ktorému možno automatizovane nájsť takú konfiguráciu algoritmu vysvetliteľnosti, ktorá poskytuje dobré vysvetlenia pre konkrétnu úlohu, je automatizovaná vysvetliteľná umelá inteligencia (Automated eXplainable AI alebo AutoXAI). Dokonca sa dá zadefinovať, čo znamená dobré vysvetlenie pre konkrétnu úlohu. Vďaka AutoXAI a optimalizácii z veľkého množstva rôznych algoritmov vysvetliteľnej umelej inteligencie získate napríklad dva, ktoré by mali na základe proxy metrík poskytovať najlepšie vysvetlenia. Jednoduchou proxy metrikou môže byť napr. dĺžka vysvetlenia, ak ide o text.
Vyhodnocovanie zamerané na človeka

Predtým než vysvetlenia sprístupníte administrátorom, overíte, do akej miery im budú pomáhať pri práci. Zároveň sa chcete presvedčiť, či vysvetlenia, ktoré vami zadefinované proxy metriky na meranie ich kvality označili ako najlepšie, budú pre ľudí najužitočnejšie. Urobíte teda A/B test. Jednej skupine administrátorov ponúknete vysvetlenia od algoritmu, ktorý vyšiel z AutoXAI ako najlepší. Ďalšej skupine poskytnete vysvetlenia z iného, o niečo menej úspešného algoritmu. Tretia skupina zostane bez vysvetlení. Následne necháte administrátorov pracovať a budete objektívne merať, koľko času potrebovali na posúdenie tých istých 200 príspevkov.
Hypotéza je, že administrátori, ktorí majú k dispozícii zdanlivo najlepšie vysvetlenia, by mali plniť úlohu najefektívnejšie. V tomto prípade by im mala zabrať najmenej času. Na opačnej strane by mali stáť administrátori bez vysvetlení.
Pri A/B testovaní sme efektívne konfrontovali to, čo nám hovoria proxy metriky vyhodnocovania zameraného na funkcionalitu s tým, ako v skutočnosti rôzne vysvetlenia pomohli človeku pri práci. Je niekoľko dobrých dôvodov, prečo je konfrontácia rôznych spôsobov vyhodnocovania kvality vysvetlení potrebná. Proxy metriky môžu byť neúplné alebo zle zadefinované. Mohlo sa napríklad stať, že uprednostňovali vernosť pred zrozumiteľnosťou a výsledné vysvetlenia tak boli príliš komplexné, v dôsledku čoho mohli pri plnení úlohy viac uškodiť ako pomôcť. Množina algoritmov vysvetliteľnej AI, z ktorých sme vyberali, neobsahovala ani jeden algoritmus vhodný pre našu úlohu, a tak aj víťazný algoritmus mohol mať pre používateľov malú pridanú hodnotu, prípadne nemal nijakú pridanú hodnotu.
Ivana Beňová, Martin Tamajka, Marcel Veselý
Kempelenov inštitút inteligentných technológií
Tento článok je súčasťou série Vysvetliteľná umelá inteligencia: od čiernych skriniek k transparentným modelom.
Projekt podporila Nadácia Pontis.